About Me

- 2021 UNL & Raikes School graduate (Cohort 2017)
- Engineering @ Layer since graduation
- Live in Lincoln, NE with my wife and kids
- Fun Fact: Enjoy gardening and DIY
- Fun Fact 2: I can ride a unicycle
About Layer
- Construction data management platform
- Used by architecture firms and job sites worldwide
Agenda
- The Problem
- Solutions Considered
- Why Local-first Won
- Technical Implementation
- Challenges & Solutions
The Problem
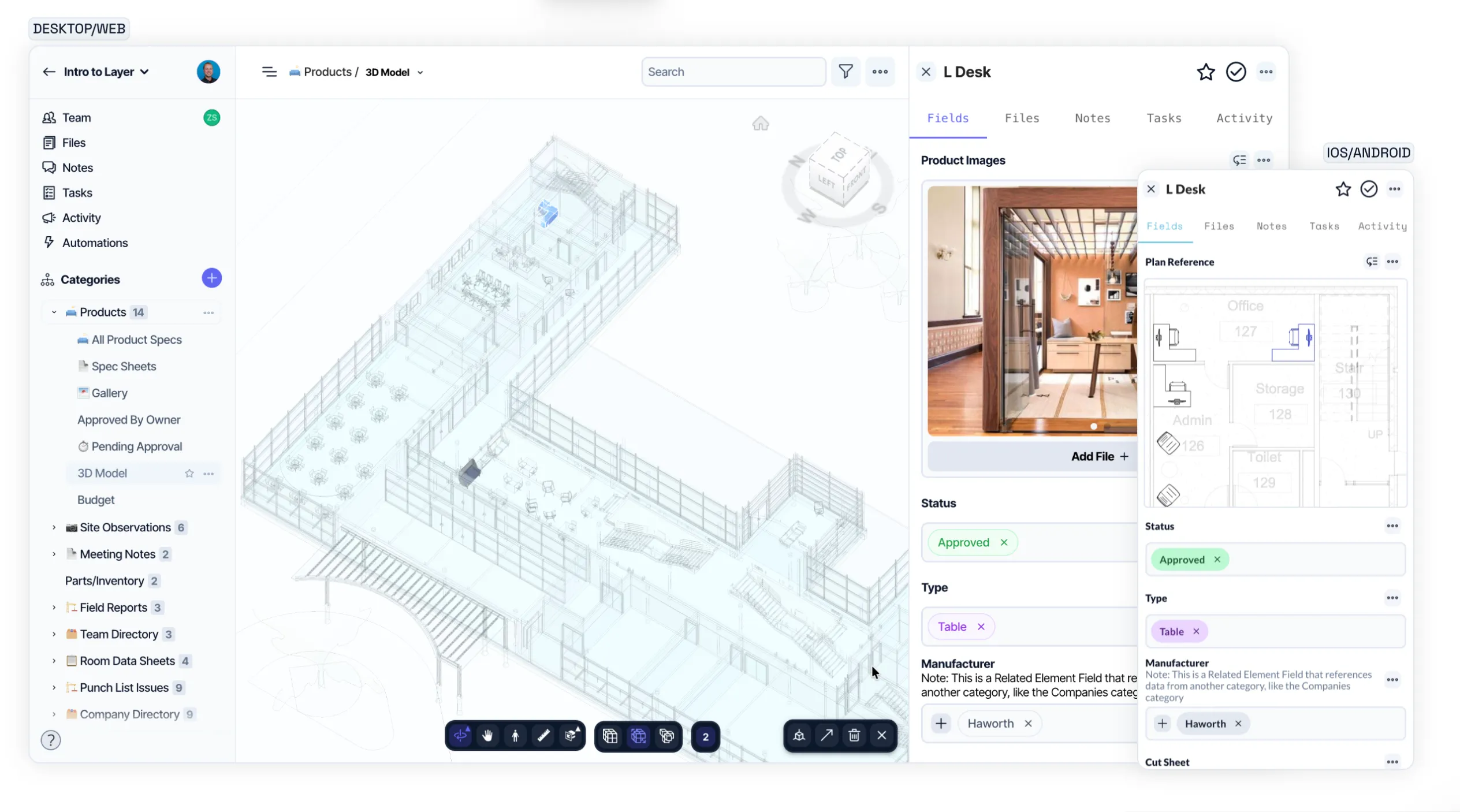
Data Relationships at Scale
- Issues: description, cost, photos, assignees
- Users: home base, specialty, contact info
- Users expect to see related data inline
- At 10k+ issues × 100s of users = 💀
Example
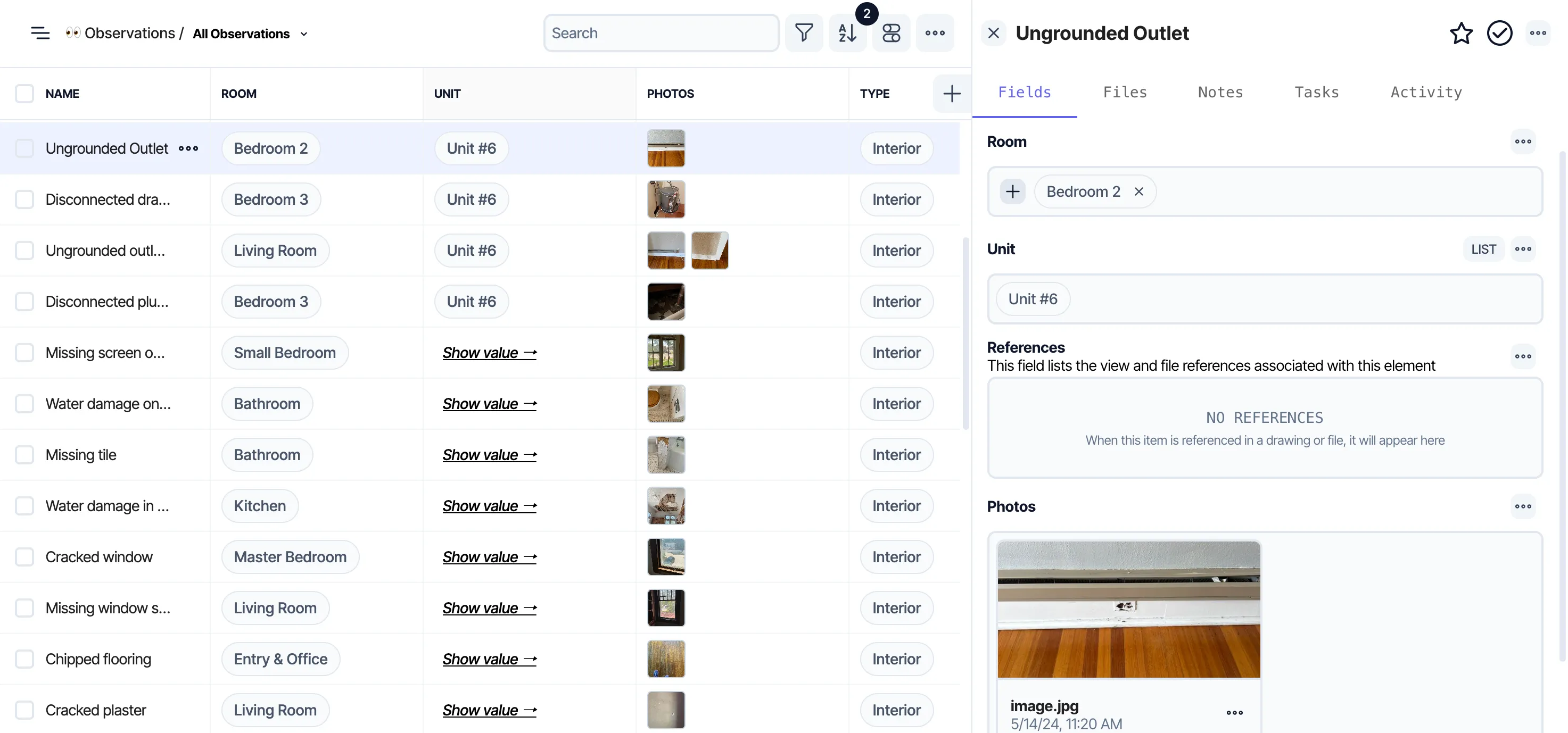
How This Impacted Users
- Limited data in table views
- Rich data only on click-through
- Same user data loaded multiple times
- Redundant requests, slower UX
Additional Pain Points
-
Data drift: stale data from failed propagations
- Offline needs: field sites don’t have WiFi
- Firestore offline wasn’t enough control
Solutions Considered
| Approach | Offline | Complexity | Scale |
|---|---|---|---|
| Direct DB Calls | ❌ | Low | Poor |
| Propagation | ❌ | Medium | Poor |
| On-Demand Reducer | ❌ | High | Variable |
| Local-first | ✅ | Medium | Excellent |
Propagation
- Copy related fields to parent documents
- Works until users want all the data
- Exponential growth in storage
- Mounting tech debt
On-Demand Loading
- Single endpoint loads all page data
- Most traditional solution
- Places least demand on user devices
- Complex, bug-prone reducers

XKCD 378: Real Programmers by Randall Munroe 2.5
Local-first
“What if all the data was just always loaded?”
- Loading data has no network cost
- Asynchronous by default, but not in practice
- Data is read and manipulated locally

Why Local-first Won
Our Advantages/Situation
- Project-scoped data: natural batching
- ~1,000–10,000 entries per project
- Feasible to load upfront
- Users expect heavy apps (Revit, etc.)
- Offline is a must for job sites
Bonus Capabilities
- Custom filtering & sorting
- Shared filter logic (front-end + back-end)
- Consistent behavior online/offline
- No loading spinners beyond initialization
- Instant Updates (No calls to ES)
- Enables stateful features
Choosing a Sync Engine
Local-first needs a sync engine to handle data flow



Released after we started implementation - not designed for NoSQL (Replicache Successor)


Emerging options (ElectricSQL, PowerSync)
Why Replicache?
- Flexible: we define push/pull endpoints
- Primarily a client library
- IndexedDB storage (battle-tested)
- Observable hooks for UI updates
- Built for NoSQL
How Replicache?





Architecture Overview
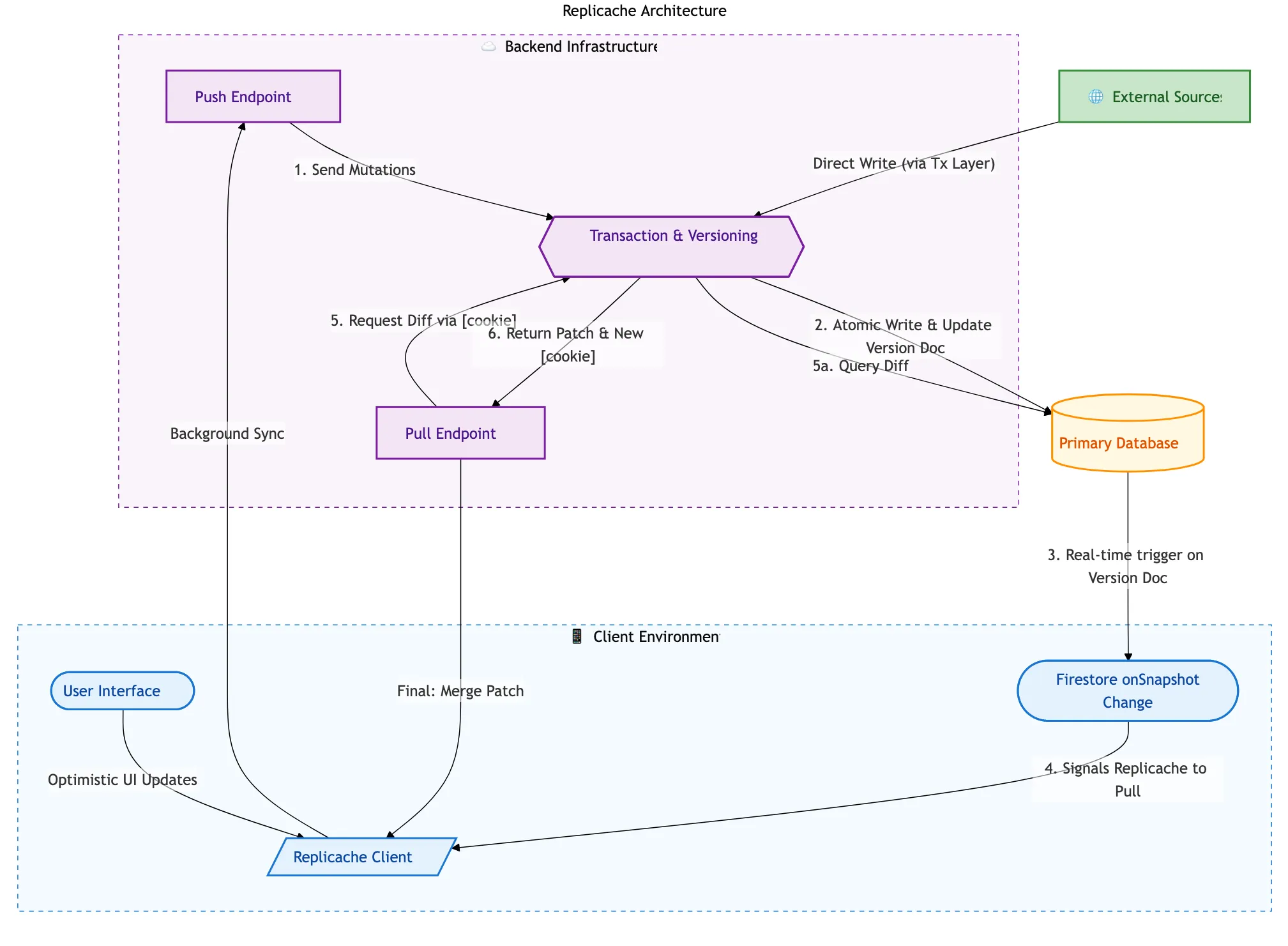
Push & Pull Endpoints
Pull
function pull(cookie): // Get changes since client's last sync point changes = getChangesSince(cookie)
// Build patches from changes patches = buildPatches(changes)
newCookie = getCurrentVersionCookie()
// Return patches and new sync point return { patches, cookie: newCookie }Push
function push(clientId, mutations): for each mutation in mutations: // Skip if already processed (idempotency) if alreadyProcessed(clientId, mutation.id): if !hasPermission(clientId, mutation): continue
// Apply mutation to server state applyMutation(mutation) recordMutationProcessed(clientId, mutation.id)
return { success: true }Architecture Components
-
Client: Replicache service wraps all data access
- Primary DB: Firestore (source of truth)
- Push: Client → Server updates
- Pull: Server → Client sync
- External: Cloud Functions, APIs - anything not directly user driven
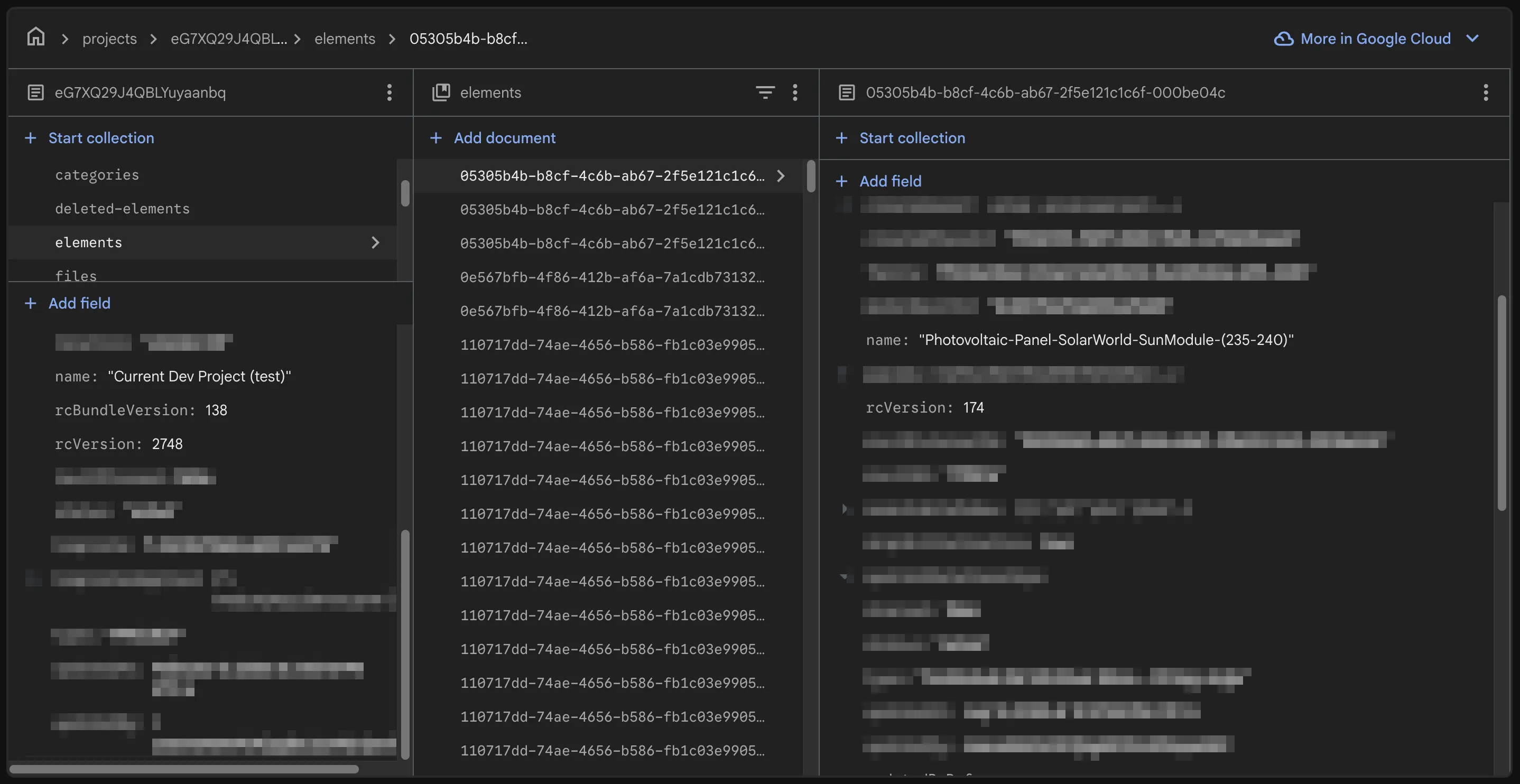
Per-Space Versioning
- Each project has its own version (
rcVersion) - Each element has its own version (
rcVersion) - Changes applied and cached locally without verions
-
Updates applied in a bulk transaction on the server, which adds versioning
Challenges & Solutions
Bootstrapping Large Projects
Problem: 40k+ element projects = ~150 - 200MB, slow initial load
- Multiple round trips (1k–10k batches)
- Serialization time on each request
-
Pull is called repeatedly until it returns no patches (complete)
Solution: Pre-serialized Bundles
- Pre-serialize project data to storage bucket
- Client fetches zipped bundle directly
- 70–90% of data instantly
- Background sync for latest changes
- Particularly helpful for projects that start out huge
Bundle Loading Code
Client Side
function pull(): lastCookie = getStoredCookie()
response = POST /pull { cookie: lastCookie }
if response.hasBundleUrl: // Bundle exists in storage - load full snapshot bundleData = downloadFromStorage(response.bundleUrl) applyPatches(bundleData.patches) storeCookie(bundleData.cookie)
// Pull again for changes since bundle was created pull() else: // No bundle - apply incremental patches applyPatches(response.patches) storeCookie(response.cookie)Server Side
function handlePull(cookie): changesSinceCookie = getChangesSince(cookie)
if cookie.fromVersion === 0: // Fresh client - serve a pre-built bundle instead bundleUrl = getLatestBundleUrl() return { bundleUrl, cookie: bundleCookie } else: // Few changes - return incremental patches patches = buildPatches(changesSinceCookie) return { patches, cookie: currentCookie }Filtering & Sorting
Problem: Loading huge amounts of data (10,000+ elements) into memory is slow
- To sort data, you have to load it all into memory
- Servers/databases solve this with indexing
- Replicache has some support indexing, but not first class
- Filtering & sorting has similar gaps
- Solution: LokiDB for in-memory indexing
- Only index data needed for filter/sort
- Watch Replicache for live updates
export interface LayerElement { autoGenerateName?: LayerAutoGenerateNameOptions; autoIncrementId?: number; category: ContextItem<R>; completed: boolean; createdAt: number | T; createdBy: R | string; createdByRef: { email: string; id: string; name: string }; createdPhaseId?: string; deletedAt?: number | T; family: string; fields: Record<string, any | LayerElementField<T, R>>; id?: string; modelRevitId: string; name: string; params: Record<string, LayerRevitParameterValue<T, R>>; rcVersion?: number; references?: { [key: string]: LayerReference<T, R> }; revitExternalId?: string; revitId: null | string; revitKind?: 'Forge' | 'Instance' | 'Type'; searchableIndex: string[]; skipInitialization?: boolean; spatialRelationships?: LayerForgeInstanceElement['spatialRelationships']; starred: boolean; status: 'active' | 'archived'; templateName?: string; type?: string; typeId?: string; updatedAt: T; updatedBy: R; updatedByRef: { email: string; id: string; name: string }; versionHistory?: LayerForgeInstanceElement['versionHistory']; viewables?: LayerForgeViewable[];}export interface LokiDBElement { _sortName: string; /** * Dynamic fields stored as key-value pairs * * Keys (IDs) represent one the following: * - A regular layer field ID (unique) * - A Revit parameter ID * - A spatial relationship ID + a categoryID (ex. 'spatialRelationships.<categoryId>') */ [id: string]: unknown; autoIncrementId: null | number; categoryId: string; completed: boolean; createdAt: number; createdBy: string; createdPhaseId?: string; id: string; modelRevitId?: string; name: string; references: string[]; spatialRelationships: string[]; starred: boolean; status: string; type?: string; updatedAt: number; updatedBy: string;}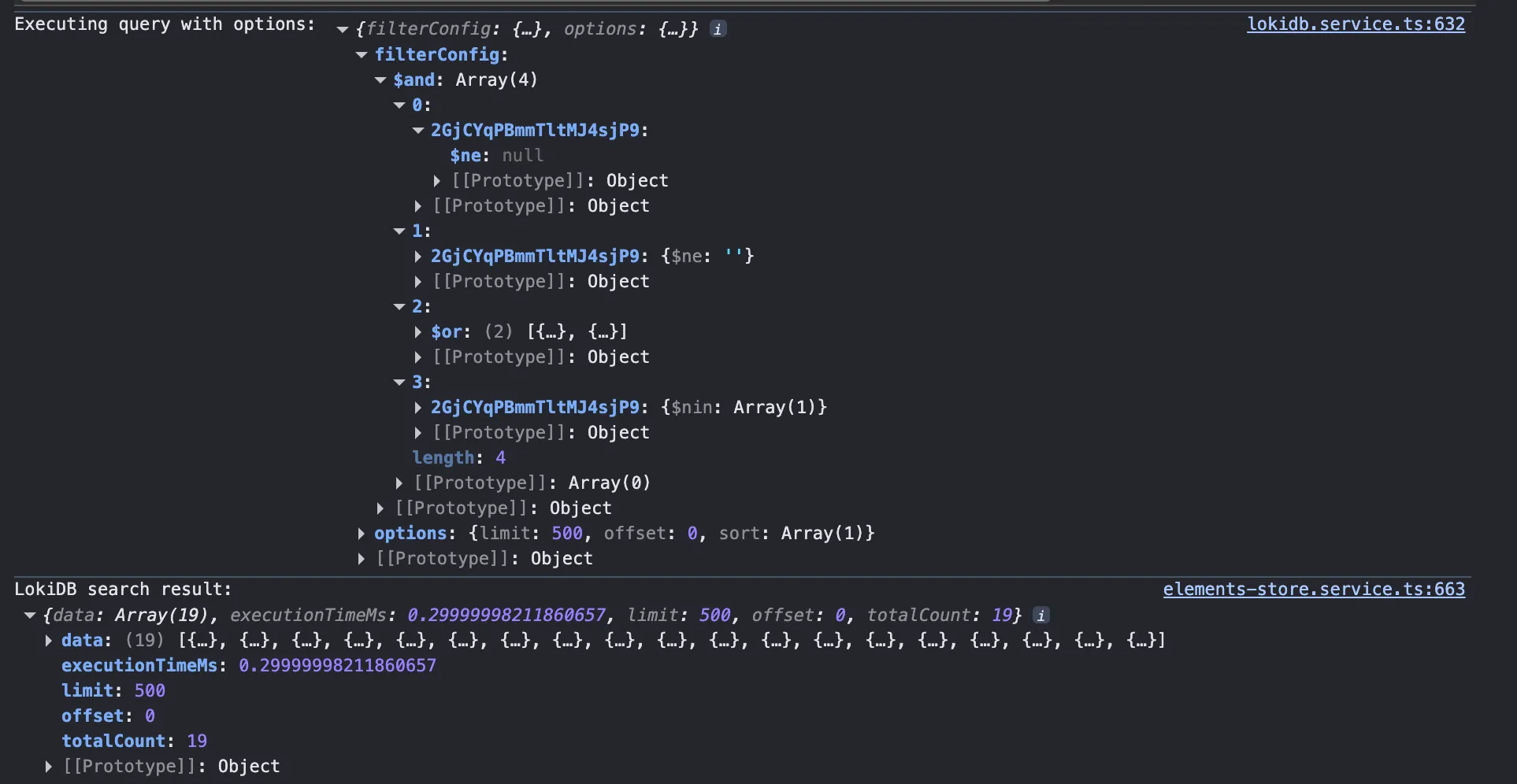
Update Contention
Problem: Backend calls to update data can fail if made in bulk due to contention
-
Client doesn’t run into this issue - can retry at will/long lived sessions
- Local changes can’t have contention
Solution: Queue + Retry
- Solution: (TODO) Cloud queue for retrying failed updates
- Failed updates are retried with backoff until they succeed
- Optionally bulk-pull similar entries from queue
Summary
- Local-first = all data available, always
- No silver bullet - overhead costs and infrastructure maintenance add complexity
- Sync engines handle eventual consistency
- Pre-serialized bundles speed up bootstrap
- In-memory indexing (LokiDB) for fast queries
- Queue + retry for update contention
Questions?
Slides & Writeup @ jackarens.com